
¿Cuántas veces has escuchado que el SEO está muerto? Seguramente muchas. Yo, por lo menos, lo llevo leyendo desde que empecé en esto del posicionamiento en 2010, si mal no recuerdo. Esto se debe a la frustración que sentimos tras años invertidos en un proyecto para que, de pronto, un cambio de algoritmo lo tumbe.
Es algo bastante común. Google, en busca de la naturalidad, necesita ofrecer un mejor resultado de cara al usuario, evoluciona y cambia para adaptarse y mejorar. Y lo hace constantemente cambiando el algoritmo con el objetivo de luchar contra las malas prácticas. Con estos cambios, se acerca cada vez más a la comprensión del lenguaje humano.
Actualmente, muchos SEO siguen trabajando con las keywords y es de lo que más se escucha hablar, pero desde hace ya varios años (concretamente desde 2012), el término de keyword empezó a evolucionar dando lugar a un nuevo término conocido como “entidad”.
Mucho se habla sobre las palabras clave, pero poco se toca el tema de las entidades en SEO: ¿qué son?, ¿para qué sirven?, ¿cómo trabajar con entidades en tus textos?
¿Qué son las entidades?
Las entidades, en SEO, son el nombre de algo, es decir, de un elemento, un lugar, una persona, un animal, un objeto, un ente, una cosa. Y este nombre se asocia de forma automática a otros términos o palabras, como pueden ser fechas, acciones u otras entidades.
El objetivo de las entidades es facilitar las respuestas al usuario en función de la intención de búsqueda de este. Los motores de búsqueda necesitan establecer relaciones entre palabras o conceptos, y esto da lugar a las entidades.
Podemos ver algunos ejemplos en la web de Microsoft, donde nos explica cómo relacionan los motores de búsqueda todo esto, cómo pasamos de un buscador normal a la necesidad de una web semántica y a la adaptación de los resultados de búsqueda. Esto lo explicaré un poco más abajo, pero antes…
¿Qué tipos de entidades existen?
Basándonos en la documentación oficial de Google para el procesamiento del lenguaje natural, las entidades que reconoce y clasifica actualmente son:
- PERSON: persona.
- LOCATION: lugar.
- ORGANIZATION: organización.
- EVENT: evento.
- WORK_OF_ART: ilustración.
- CONSUMER_GOOD: productos de consumo.
- OTHER: otros tipos de entidades no identificadas.
- PHONE_NUMBER: número de teléfono.
- ADDRESS: dirección.
- DATE: fecha.
- NUMBER: número.
- PRICE: precio.
- UNKNOW: para entidades desconocidas.
Evolución del motor de búsqueda y llegada de la web semántica
Poco a poco, los dispositivos desde los que se han conectado los usuarios han ido evolucionando y, en paralelo, también han cambiado las búsquedas que estos hacían para satisfacer las necesidades que tenían.
Desde los ordenadores de escritorio siempre ha sido más común realizar búsquedas cortas, pero con el paso del tiempo y el acceso de más población a los buscadores, comenzaron a surgir búsquedas más largas que necesitaban ser respondidas con más exactitud; y con la llegada de los móviles, este hecho no solo se intensificó más, sino que dio lugar a más diversidad de búsquedas.
Ante el problema de poder dar una respuesta más exacta al usuario y conocer la intención de búsqueda que se esconde tras cada una de esas búsquedas, se establecieron las entidades para ofrecer mejores resultados al usuario.

Estas entidades, como expliqué al principio del post, se relacionan para poder dar esta respuesta al usuario, por lo que si buscamos el nombre de un actor, es posible que estemos buscando fotos, la biografía o películas en las que ha participado. Y si buscamos una ciudad, es posible que necesitemos ver un mapa, noticias, alquileres, compra de viviendas, etc.

Cómo es Google capaz de entender la relación de palabras
Es necesario irse un poco atrás en el tiempo para recuperar y entender algunos términos relacionados con las técnicas empleadas para comprender mucho mejor la relación de contenidos y de qué se está hablando en cada uno de ellos.
- Cocitación: cuando un texto cita a dos referencias de otros dos textos, dándose la probabilidad de que estas dos referencias estén relacionadas entre ellas y el texto que las referencia. La probabilidad de relación va disminuyendo cuanto mayor es la distancia entre las dos referencias, y aumenta si la distancia es menor.
- Coocurrencia: es la relación de proximidad entre términos que aparecen en un texto y las diferentes partes que forman este texto. Si dos términos están juntos o cercanos, probablemente estén relacionados de forma semántica.
- LSA (Latent Semantic Analysis): en español se conoce como Indexación Semántica Latente. Es un método de indexación que trata de buscar patrones de relaciones entre los términos de un conjunto de documentos. Aquí creo que hay hacer una desambiguación con otro término que deriva de este concepto, conocido como keywords LSI, que sería la relación de palabras dentro de un mismo documento para poder entender de qué tema está tratando.
- Ontología: trata de dotar a los ordenadores de la capacidad de valorar información por sí mismos mediante el uso de inteligencia artificial.
Una vez conocidos estos términos, podemos hacernos una ligera idea de cómo ha evolucionado el análisis de contenidos por parte de Google y cómo cada uno de estos aún sigue vigente y de qué forma funcionan.
Gracias a la cocitación, Google es capaz de realizar un análisis sobre lo que habla cada contenido en función de la proximidad de los enlaces. Por eso, es tan importante que haya relación entre la temática de nuestros artículos y la de los artículos que nos enlazan.
El siguiente paso es la coocurrencia, que tiene un doble efecto.
Por un lado, tenemos las palabras que rodean a los enlaces que apuntan a nuestras páginas. La cercanía de estas hace que Google pueda entender mucho mejor de qué trata el contenido enlazado.
Por el otro lado, tenemos la relación de palabras, frases y párrafos, en relación con la distancia que existe entre estos. Si además le sumamos las keywords LSI, el algoritmo de Google BERT, que ya conocemos y que refuerza el entendimiento del contenido basándose en un contexto, tenemos un avance importante.
Por último, pasaríamos al método de indexación en relación con el conjunto de documentos relacionados (LSA). Esto lo que haría sería mostrar información de algo si muestra información de otra cosa relacionada, de ahí que cuando busques un concepto, muchas veces, Google te muestre información relacionada, como veremos a continuación en el knowledge graph.
Knowledge graph
Una forma de ver todo esto, de cómo Google relaciona la información mediante entidades, es el knowledge graph (gráfico de conocimiento). Aquí están los destacados que aparecen en los resultados de búsqueda aportando más información sobre una consulta.
Inicialmente, toda esta información se extrajo de fuentes como Wikipedia, Wikidata, Freebase entre otros, pero también se ofreció la posibilidad a otras webs de insertar un marcado que pudiera ofrecer más información y que todo esto se viera retroalimentado. Con este marcado nacieron los microformatos, RDFa, schema, etc.
Si realizas una búsqueda como puede ser “Madrid”, podemos ver el siguiente knowledge graph de la entidad Madrid:

Como resultado, nos ofrece el país al que pertenece, el tiempo, el gentilicio, el patrón, la población, información sobre hoteles, vuelos, planificaciones de viajes, etc.
Otro ejemplo sería la búsqueda del título de una película o una persona conocida. En este caso, escogí “Aladdín”:

Así, podemos obtener información relevante de entidades; por ejemplo, personas relacionadas con la película como puede ser el director o el reparto, plataformas donde puedes ver la película y quién hizo posible la producción de esta, fecha del estreno, etc.
Extraer entidades
Existen otras formas además de los knowledge graph para extraer entidades. Para ello, podemos recurrir a herramientas que nos ayuden a identificarlas.
Si queremos obtener sugerencias de entidades para una keyword en concreto, tan solo tenemos que ir a Google Imágenes y realizar una búsqueda rápida.

Esos pequeños bloques con keywords que aparecen en la parte superior de las imágenes son entidades que podemos usar para reforzar nuestros contenidos.
Carlos Ortega también nos ofrece este magnífico hilo de X donde nos deja algunos trucos para extraer entidades:
Seguro que sabéis que para ver las entidades de un texto podéis tirar de la API de NLP de Google.
Pero, ¿sabéis también de dónde más se pueden sacar entidades de forma gratuita?
De GOOGLE DOCS 😱
Mini hilo ⬇️
— Carlos Ortega (@carlos_darko) May 20, 2020
Si nos queremos meter a hilar un poco más fino, os contaré algunas opciones más, pero que requieren de un registro previo en Dandelion, haciendo uso de su versión gratuita (siempre que no necesites hacer un uso excesivo de la herramienta).
El ejemplo que expondré se basará en la consulta anchor text.
Extensión de Chrome
Una de ellas es una extensión de Chrome, realizada por Fede Gómez, llamada extractor de entidades.
Una vez instalada nos pedirá que insertemos un token API de la web de Dandelion, por lo que necesitaremos registrarnos en esta web y acceder a nuestro Dashboard para encontrar el token API.

Una vez introducido el token, podemos guardar y cerrar para empezar a probar la extensión.
Para ver su funcionamiento, debemos realizar una búsqueda rápida en Google y pulsar sobre el icono del plugin o en el desplegable; después hacemos clic sobre extractor de entidades.
Tarda unos segundos en aparecer, por lo que tendréis que esperar un poco a que realice el análisis y muestre la información. Lo que podréis ver son las entidades por cada resultado de búsqueda justo debajo de cada resultado en las SERP.
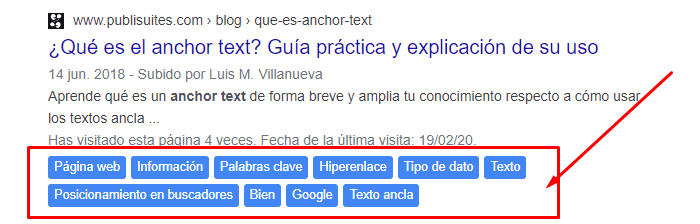
En este bloque también podremos ver más información sobre cada entidad si hacemos clic en cada uno de los resultados.
Por otra parte, también veremos una media de todas las entidades en función de los resultados de búsqueda en la parte derecha de la pantalla.

Se ordenarán por nivel de relevancia y distinguiremos claramente su importancia mediante el color azul. También tendremos la opción de ver todas las entidades o exportar la información en un CSV.

Entidades SEO Kiwosan
Kiwosan es una herramienta de pago, pero no es muy cara y ofrece otras funcionalidades bastante interesantes. En el análisis de entidades que te ofrece, revisa los primeros resultados de Google para analizar estas entidades, y también permite que mandes tú las URL seleccionadas para realizar este análisis de entidades.

En el primer desplegable podemos seleccionar si queremos analizar las entidades de las SERP o analizar URL personalizadas con la opción Batch. En el segundo recuadro, insertaremos la consulta o listado de URL, y en el tercero seleccionaremos el país (aunque actualmente solo está España seleccionable).
Tras realizar la consulta, lo primero que veremos será una gráfica con las entidades ordenadas por apariciones.

Lo siguiente que veremos será una tabla en la que la primera columna estará constituida por las entidades más usadas y su relación con el contenido, para después pasar al análisis de entidades por cada URL.
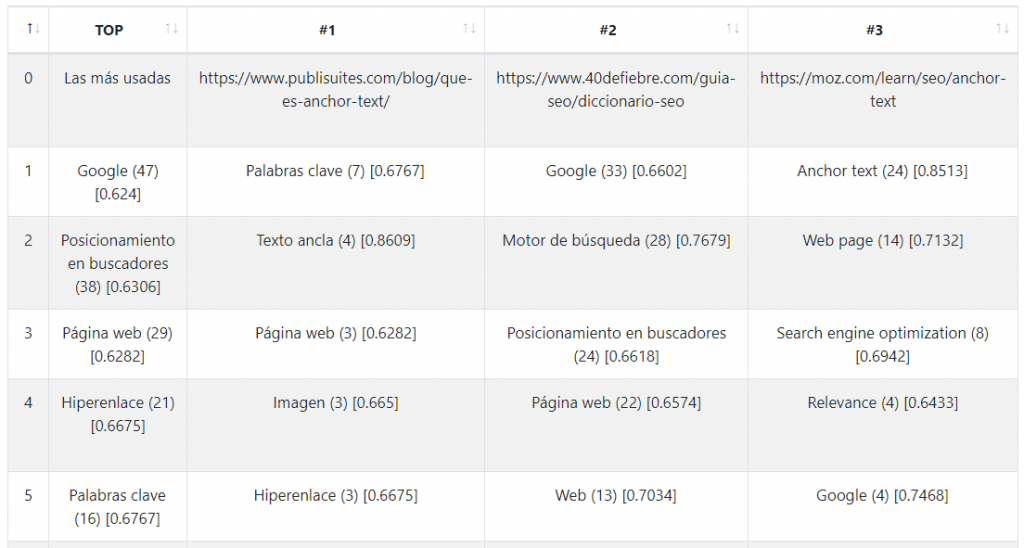
En cada recuadro de entidad aparece:
Nombre de la entidad (número de veces que aparece) [importancia de la entidad]
Lo siguiente que vemos es la clasificación y el análisis de estas entidades por tipos en relación con la documentación oficial del procesamiento del lenguaje natural que comenté más arriba.
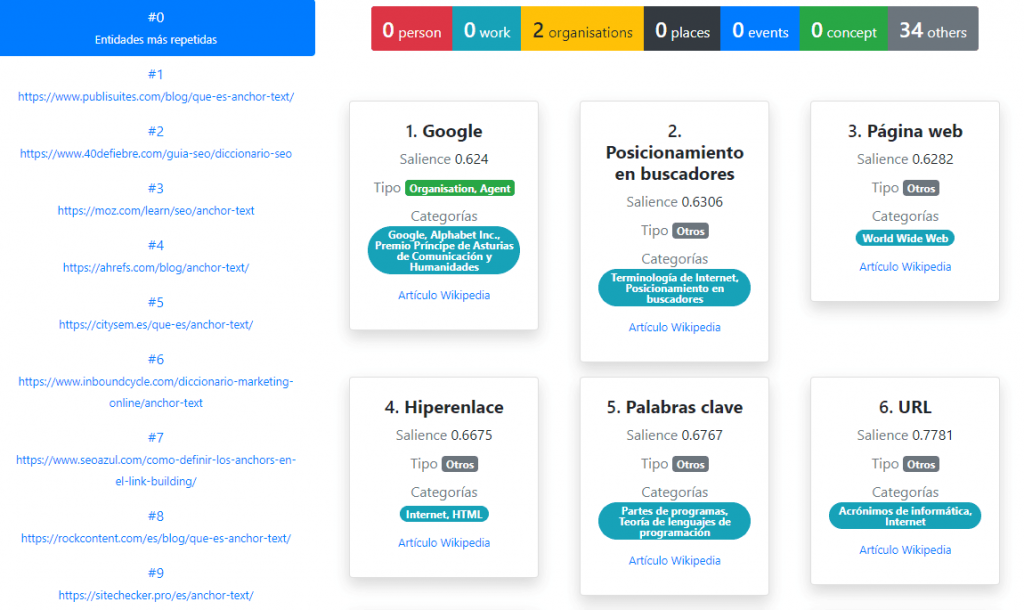
Los tipos se pueden ver destacados en colores en la parte superior a modo de total, pero también podemos ver a qué tipo de entidad pertenece cada una de forma individual en cada tarjeta donde pone “Tipo”.
¿Cómo ayudan las entidades a enriquecer un texto?
Ahora que hemos extraído todas las entidades de los textos: ¿cómo puede ayudarnos esto en el SEO?, ¿cómo debo trabajar con las entidades para posicionar un texto?
Es tan sencillo como insertar las entidades tal cual en nuestro contenido, dando mayor importancia a aquellas que tengan mayor valor de importancia en el top de entidades y que estén dentro de algún tipo de clasificación distinto a others o unknow.
Conclusiones
El concepto de las entidades es algo bastante complejo de entender, pero la forma de trabajar con estas es bastante sencilla.
Existen herramientas que están al alcance de todos y nos pueden ayudar a realizar este análisis y a entender mucho mejor la intención búsqueda de los usuarios.
Si a esta técnica le aplicamos también el análisis de TF-IDF y creamos artículos orientados, como expliqué en el artículo de intención de búsqueda, conseguiremos unos textos perfectos para optar unas buenas posiciones.



4 comentarios en “Qué son las entidades SEO y cómo utilizarlas para mejorar tus textos”
Hola Eric. Muchas gracias por ese artículo fascinante. No solo explicas la parte conceptual sino que vas a lo práctico. Un saludo.
Gracia Eric. Buen tema lo desconocia pot completo .
Gracias Eric, su artículo es ilustrativo, su contenido enriquece la capacidad de escribir para web, en mi caso es de gran ayuda. Saludos.
Pingback: ¿Cómo se ganó el concurso SEO?