
Una de las herramientas más usadas por todos los SEO son los crawlers. Facilitan el trabajo ya que permiten rastrear tu web y sacar errores comunes de la parte SEO on page.
La herramienta más extendida de estos crawlers es Screaming Frog Seo Spider. Hoy hablaré de él y daré algunos consejos para empezar a trabajar con esta herramienta (aunque existen otras alternativas como Sitebulb o Netpeak Spider que recomiendo probar también, ya que el uso es similar).
¿Qué es Screaming Frog Seo Spider?
Screaming Frog Seo Spider es una crawler, también conocido como robot o araña web.
Este tipo de herramientas se dedican a obtener información directa de la web seleccionada, rastreando cada página a partir de los enlaces que contiene y de la configuración del crawler, así como del fichero robots.txt.
¿Para qué puedes usar Screaming Frog?
Es útil para detectar errores internos de páginas, enlaces que apuntan a redirecciones, problemas con title, h1 y descriptions, errores de enlazado interno, indexación, etc.
Antes de empezar con el tutorial, hay que saber que la herramienta no es gratis en su totalidad.
Versión gratuita y versión de pago
Screaming Frog Seo Spider cuenta con 2 versiones, una gratuita y una de pago.
Con la versión de pago tienes acceso a toda la herramienta, mientras que la versión gratuita solo permite:
- Límite de crawleo a 500 URL
- Encontrar errores en enlaces y redirecciones
- Analizar los titles de las páginas y los metadatos
- Revisar Meta Robots y directivas
- Auditar los atributos hreflang
- Detectar páginas duplicadas
- Crear sitemap XML
- Site Visualizations
Las opciones avanzadas como programar crawleos, probar ficheros robots.txt personalizados, extraer información personalizada de la web, etc., quedan fuera.
Puedes encontrar todas las ventajas que te ofrece la versión de pago aquí.
Ahora sí, vamos al turrón. Veamos cómo usar esta herramienta para aplicar mejoras en una web.

Tutorial básico de Screaming Frog Spider
Antes que nada es necesario descargar la herramienta desde la web oficial de Screaming Frog, pulsando sobre uno de los dos botones que pone Download.

Una vez instalado, lo primero que tienes que hacer es abrir la herramienta y verás una pantalla como la siguiente o muy similar (puede cambiar ligeramente en función de la versión instalada, pero con el paso de los años, la interfaz no ha cambiado prácticamente).
Al abrir la aplicación verás lo siguiente:

¿Qué puedes hacer con Screaming Frog?
Crawlear una web con Scremaing Frog
Para empezar a probar la herramienta y sacar los errores de una web, es tan fácil como insertar el nombre del dominio y darle a Start:

Al pulsar sobre Start, el robot empezará a realizar su trabajo y rastreará la web, por lo que deberás esperar a que finalice el proceso.
Dependiendo del tamaño de la web , puede tardar mucho o poco, pero por lo general no más de 1 hora o 30 minutos para webs de un tamaño medio.En la parte superior de la web verás el estado de progresión del rastreo, mientras que en la parte inferior veras las URL totales, procesadas y restantes. Por lo general, las URL totales suelen ir aumentando conforme va encontrando nuevos enlaces.
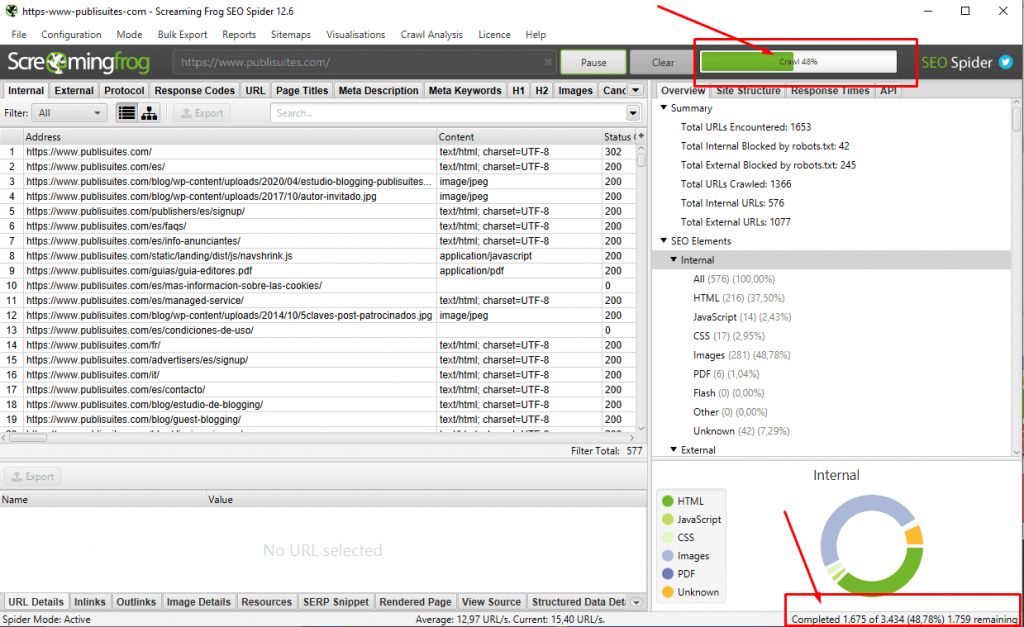
Una vez finalizado el proceso, podrás empezar a detectar algunos problemas dentro de la web para aplicar mejoras.
Protocolo
Desde hace algún tiempo, Google recomendó que los sitios debían estar en https. Aún no se han encontrado casos en los que el cambio de protocolo afecte realmente al posicionamiento, pero nunca está de más hacer caso en esto.
En la parte de Overview de la aplicación, en el apartado de Protocol (1), debemos seleccionar el apartado de http.
La pantalla de la izquierda cambiará mostrando todos los enlaces que tiene nuestra web apuntando a URL http (2), por lo que deberás cambiar estos enlaces a https.
Si quieres saber dónde se encuentran estos enlaces, debes pulsar encima de ellos, y en la parte inferior de la aplicación, haciendo clic en inlinks, podrás ver las páginas donde se encuentran dichos enlaces y el anchor text o alt del enlace, así como otras características de estos.

Para cambiar los enlaces internos de http a https rápidamente en WordPress, así como toda la configuración a https, puedes usar el plugin Really Simple SSL, que cambiará tu web a este protocolo de seguridad. Lo único que no cambiarán serán los enlaces externos de tu web.
Para modificar los enlaces externos puedes usar algún plugin de Search & Replace, para hacer búsquedas rápidas y reemplazar en tu base de datos. Es recomendable que antes de usar el plugin, hagas una copia de seguridad de tu base de datos.
Por último, si tras hacer estos cambios aún quedan enlaces en http, es posible que estén incrustados directamente en el código de la web, ya sea del propio tema o de algún plugin, por lo que tendrás que buscar en qué parte del código se encuentra y corregirlo.
Para hacer esto, puedes descargarte los ficheros y hacer una búsqueda con Sublime, que te permite hacer búsqueda del contenido de ficheros a partir de una carpeta seleccionada.
🐸 Guía de Screaming Frog ¿Qué puedes hacer con esta herramienta para mejorar tu web? Compartir en XCódigos de respuesta
Los códigos de respuesta proporcionan información sobre problemas en el rastreo.
Veamos cómo solucionar los problemas más comunes y si realmente suponen un problema.
Blocked by Robots.txt
Estas URL son aquellas que están bloqueadas por robots.txt. Normalmente son URL que están enlazadas de forma interna por usabilidad, pero lo ideal es que el robot no acceda a ellas.
El objetivo aquí sería reducir en lo posible los enlaces a dichas páginas para mejorar el enlazado interno de nuestra web.
Para ver la procedencia de los enlaces, el método es el mismo que el mostrado para ver las páginas que enlazan a protocolos http (visto anteriormente). Nos vamos a Response Codes, seleccionamos Blocked by robots.txt, clic en la URL y finalmente clic en la pestaña inferior de Inlinks.
Otra opción a considerar es la de la ofuscación de enlaces; aunque es penalizable, muchos sitios la utilizan. Para hacer esto con WordPress fácilmente tienes el plugin de Fede Gomez Link Juice Optimizer, es gratuito pero acepta donaciones (hay que ser agradecido en la vida, jeje).
Blocked Resource
Son recursos bloqueados al robot. Esto impedirá que pueda renderizar bien la página y el robot a nivel estético la vea mal.
Es recomendable corregir esto, normalmente desde el fichero robots.txt.
No Response
Son páginas que no han dado respuesta. Normalmente, esto es por sobrecarga del servidor o porque la propia configuración bloquea las peticiones si son demasiadas. Suele ser un problema técnico que es recomendable revisar y solucionar.
Normalmente necesitarás hablar con tu proveedor de hosting para ver qué sucede y que te ofrezcan alguna solución al problema.
Redirection
Son enlaces detectados que apuntan a redirecciones.
Por regla general vamos a tratar que estos enlaces apunten a la URL final para optimizar el proceso de rastreo de los crawlers, pero no siempre vamos a poder hacer esto, dependerá de la respuesta de dirección y las necesidades del proyecto:
- 301: estos enlaces deberemos cambiarlos por los enlaces finales
- 302: son redirecciones temporales, por lo que lo lógico es que, con el tiempo, estas URL vuelvan a estar visibles. En estas situaciones es cuestión de valorar el caso en cuestión y la cantidad de enlaces que existen apuntando a la página; se podría mantener, pero en función del caso.
- 307: son redirecciones de protocolo http a https. Es recomendable cambiar estos enlaces.
Client Error
Este tipo de enlaces son problemas que ha detectado el robot al tratar de rastrear el enlace, normalmente porque la página ya no existe (404) o porque se le ha prohibido el acceso (403).
En el caso de los enlaces con respuesta 404, es conveniente corregir los enlaces para que apunten a la URL correcta o eliminarlos.
Si detectas enlaces con respuesta 403 puedes cambiarlos, quitarlos, insertarles nofollow u ofuscar estos enlaces.
Server Error
Los errores de servidor normalmente tienen el valor 5XX.
Por lo general son problemas momentáneos del servidor, pero si suceden a menudo es conveniente revisar lo que sucede con tu proveedor.
Si son enlaces externos, puedes tratar de hablar con la web en cuestión o modificar el enlace a otra página que no genere problemas.
Problemas en URLS

Por lo general, Google no es muy fan de leer los siguientes elementos en las URL:
- Barra bajas (_)
- Carácteres ASCII
- Mayúsculas
- Parámetros
Es por ello que si en el apartado de URL detectas estas características, es recomendable cambiar las URL por a URL amigables.

Title, Description y h1
Estos tres apartados son bastante similares, nos dan información sobre:
- Páginas que no contienen Title, description ni h1.
- Páginas que las contienen duplicadas o la tienen repetida dentro de ella misma.
- Tamaño máximo y mínimo de estos elementos, tanto en caracteres como en píxeles.
Aquí es bastante sencillo el procedimiento para los titles, descriptions y h1:
- Si no tienen (Missing), se les debe insertar.
- Si no están dentro del tamaño indicado, ya sea de caracteres o píxeles, se deben ajustar. Esto lo vimos en el artículo que hablábamos de TF IDF.
- Si el title y h1, coinciden se deben ajustar para que sean diferentes.
- Si están duplicados en otras páginas, debemos ver por qué se repiten. Existen casos como las paginaciones que son bastante comunes, pero si son páginas distintas, deberemos modificar estos datos.
- Si se repiten dentro de una misma página, deberemos dejar solo uno.
Imágenes
El apartado de imágenes es bastante interesante, ya que con él puedes encontrar imágenes muy pesadas que vuelven lenta la carga de la web o nos muestra oportunidades donde agregar contenido de texto a través del atributo alt.
El contenido del atributo alt de las imágenes, también conocido como texto alternativo, es recomendable que esté relacionado con lo que muestra la foto y la palabra clave que quieres posicionar en cada una de las páginas insertadas donde se encuentra.
Peso de las imágenes
Para optimizar rápidamente las imágenes de tu web puedes utilizar el plugin Smush de WordPress, aunque existen otros plugins de optimización de velocidad que también ofrecen esta posibilidad.
Otra opción es cambiar las imágenes a formatos de nueva generación como WebP que pesan bastante menos (aunque hay que ir con ojo con esto porque en algunos navegadores son incompatibles actualmente).
Para poder subir imágenes de tipo webP a WordPress necesitarás insertar el siguiente código al fichero functions.php. Se encuentra en Apariencia > Editor del panel de administrador de WordPress
add_filter('upload_mimes','webp_mime_type');
function webp_mime_type($mimes){
return array_merge($mimes, array(
'webp' => 'image/webp'
));
}
Para trabajar en la compresión de imágenes WebP en WordPress tienes el plugin de Imagify.
Estructura del sitio web
La estructura del sitio web se puede ver en la pestaña Site Structure, que se encuentra justo debajo de la barra de rastreo de la web:

Es interesante, ya que muestra dónde se encuentran la mayoría de nuestras páginas a nivel de profundidad (es decir clics de distancia de la home).

En este caso, la mayoría de URL se encuentran en profundidad 4 en adelante. Para mejorar esto, se puede optar por:
- Insertar enlaces a páginas profundas desde la home o páginas a un clic.
- Insertar o incrementar la cantidad de artículos relacionados en el blog a través de algún plugin.
- Hacer artículos recopilatorios.
- Crear un Sitemap HTML.
¿Cómo saber el nivel de profundidad o Crawl Depth de una URL en Screaming Frog?
Si se quiere ver y analizar qué URL son las que se encuentran y a qué nivel de profundidad están, volviendo a la pestaña de Overview (al lado de la pestaña de Site Estructure), justo en la parte superior del bloque izquierdo, podemos ver todas las páginas HTML y su profundidad de página:

La columna Crawl Dept tendrás que moverla haciendo click en su nombre y arrastrando.
También puedes pulsar sobre el + que se encuentra en la tabla para quitar los elementos que no quieres ver:

API
Screaming Frog también te ofrece la posibilidad de cruzar los datos de tu rastreo con varias API. Actualmente están disponibles:
- Herramientas con acceso gratuito a su API:
- Google Analytics
- Google Search Console
- PageSpeed Insights
- Herramientas con acceso de pago a su API:
- Majestic
- Ahrefs
- Mozscape
Esta información se puede ver con el resto de datos en bruto desde Overview > SEO Elements > Internal > HTML o en la parte final del Overview para ver los datos por separado.
La funcionalidad de las API es bastante útil, ya que permite comparar información como:
- URL con enlaces y mucho tráfico o viceversa.
- Cantidad de palabras/velocidad con el tráfico y los objetivos.
- Relacionar impresiones con enlaces internos y externos.
Estos son algunos ejemplos de información que podemos extraer y comparar.
Por lo general, yo suelo exportar estos datos a Excel y los trabajo con tablas dinámicas y filtros, para poder detectar mucho mejor nuevas posibilidades de mejora en la web.
En Publisuites ponemos a tu disposición más de 9.000 medios segmentados por temática, idioma, precio, tráfico y métricas SEO para que mejores la autoridad de tu web y despegues en el ranking.
Solo necesitas hacerte una cuenta de anunciante y podrás acceder a ver todos los medios.
Extraction
Por último (a pesar de que la herramienta tiene muchas funcionalidades y podría estar hablando bastante más), quiero destacar una funcionalidad bastante interesante: es la opción de extraction.
Esta función te permite extraer información personalizada directamente desde la web.
Por ejemplo, imagina que necesitas extraer el nombre de los autores de un blog y el número de comentarios, así como likes por artículo de un blog, para valorar la relevancia de los artículos en base a los autores y temáticas de los artículos.
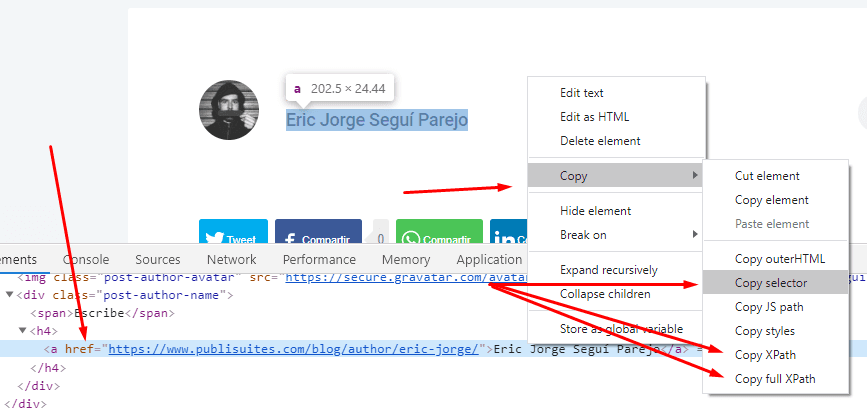
Para ello, es necesario acceder a una de las páginas que contenga la información, como puede ser un artículo del blog. Buscas el dato que quieres extraer. Con el ratón encima del elemento, haces click derecho y vas a inspeccionar:

Al hacerlo aparecerá una ventana de código en la parte superior, al pasar el ratón se iluminaran los elementos de la web. Trata de encontrar el elemento html que te proporciona la información que necesitas y pulsa el botón derecho de nuevo del ratón, en Copy, puedes elegir entre Selector, XPath o Full Xpath.
Yo seleccioné Copy Selector en este ejemplo para el nombre del autor y los likes. Para el número de comentarios seleccioné el XPath.
Ahora accedes a Screaming Frog en Configuration > Custom > Extraction dentro de Screaming Frog:
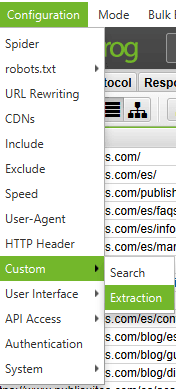
En la ventana que se abrirá, pulsas sobre Add si tienes una de las nuevas versiones de Screaming Frog (en las versiones antiguas te permite insertar la regla directamente).

Es importante que la regla seleccionada sea la copiada y que en la barra de al lado se introduzca el valor copiado.
En el desplegable de la derecha dependiendo de la información que te interese extraer, puedes optar por sacar el código HTML, el texto o el elemento HTML. También puedes rellenar el campo Atribute si lo que quieres es sacar el valor de un atributo del elemento HTML, pero esto es algo más avanzado y es difícil que lo necesites.
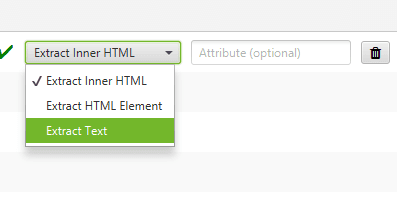
En mi caso, seleccioné Extract Text, ya que lo que quiero sacar para el ejemplo es el texto.
Importante, antes de Guardar y realizar el crawleo, inserta un nombre para cada una de las nuevas dimensiones:

Al terminar, encontrarás la información en Custom Extraction o en Internal > HTML.
Después verás algo de este tipo en tus datos:

Como se puede observar en la imagen, utilizo también el filtro superior para ver directamente los artículos donde se encuentra el nombre del autor y el número de comentarios y likes, que es en el blog.
Gracias a esto he detectado detectado que el artículo con más comentarios fue el de Bruno Ramos sobre monetización en Adsense, y el que más likes tiene es el de https://www.publisuites.com/blog/wp-content/uploads/2015/01/afiliados-publisuites-1.jpg donde te explica las claves para comprar un post patrocinado.
A esta técnica de sacar información de una web, se le llama realizar scrapping.
Conclusiones
Screaming Frog Seo Spider es una herramienta bastante completa. Te permite detectar varios errores de tu web además de cruzar datos o sacar información de otras páginas webs para poder analizar.
He querido hacer un repaso básico por las funciones más sencillas pero que te serán de gran utilidad para mejorar tu SEO on page.
Las funcionalidades de cruzar datos mediante API y extracción personalizada de información son dos funcionalidades bastante potentes e interesantes que, con algo de creatividad, permiten sacar información realmente útil que te puede servir de gran ayuda.
No explico toda la herramienta ya que tiene muchas funcionalidades, pero si tienes alguna duda sobre ella, pregunta en los comentarios y te contestaré.



13 comentarios en “Guía de Screaming Frog. Te enseñamos cómo mejorar tu web con esta herramienta”
Gran artículo. Muchas gracias.
Me acabo de instalar la herramienta, pero al tratar de analizar mi web https://soymatematicas.com/ no puedo.
¿Podéis decirme a que se debe?
Gracias. Saludos
Hola Justo!
1.-Es posible que tengas capada la herramienta desde el servidor.
Puedes probar a modificar el user-agent de la herramienta desde «Configuration» -> «User-Agent». En el desplegable, prueba a modificarlo por Googlebot (Smartphone) por ejemplo.
La mayoría de veces se soluciona con este pequeño cambio en la configuración del crawler.
2.- También es posible que tengas bloqueada tu web por robots.txt o por la propia configuración del WordPress si utilizas este CMS, prueba a revisar en «Ajustes» -> «Lectura» , revisa que no tengas la opción marcada de «Visibilidad en los motores de búsqueda».
Si esto está correcto, revisa la configuración con robots.txt, esto lo puedes ver con Yoast o con rankmath. También puedes acceder a la raíz del ftp donde tienes instalado WordPress.
Asegúrate que en el fichero no ponga una instrucción tipo esto:
User-agent: *
Disallow: /
Aquí tienes más información sobre la creación de este archivo:
https://support.google.com/webmasters/answer/6062596?hl=es
3.-Si tras seguir estos pasos sigues sin poder, te recomiendo que mandes un ticket a los proveedores tu servicio de hosting porque será cosa de ellos.
Espero que esto pueda ayudar.
=)
Muy interesante! Un buen post para guardar y tenerlo a mano cuando tenga que usar la herramienta 🙂
Muchas gracias Jessica!
Me alegra que te guste el post ^_^
Cualquier consulta que tengas, no dudes en preguntar =)
Hola, Un post muy bien explicado y muy interesante.
Habrá que probarlo por el bien de nuestros blogs.
Toda la información que se obtenga es poca.
Gracias.
Gracias!
Me alegra que te guste la guía de screaming frog que preparé.
Cualquier consulta, pregunta y te responderé =)
Es una gran herramienta la cual nos permite analizar factores importantes de nuestro sitio web, y en base a los resultados tomar decisiones para mejorar el SEO de nuestra web, vale aclarar su interfaz es simple y sencilla de usar, así como bastante intuitiva. Excelente explicación sobre como usarla!
Concuerdo con que es una gran herramienta, aunque interfaz sencilla…no sabría que decirte jeje.
Creo que toca ya que renueven un poco la interfaz o que la mejoren para incorporar algo de información más visual.
Si sabes de SEO y por donde tirar, es fácil saber que solucionar, pero por ejemplo, existen otros competidores que directamente te dicen que tienes que hacer o son mucho más intuitivas de manejar ya que incorporan gráficas y paneles mucho más simples y descriptivos.
Gracias Ivan por tu comentario y me alegra que te guste la guía =)
Wow
Menuda guía y súper bien explicada muchísimas gracias!
Nos pondremos manos a la obra en nuestros proyectos.
http://www.estudioenxebre.com
Un saludo
Excelente Eric, justamente empezamos una restructuración de nuestro sitio https://pulsodigital.com.mx y la semana pasada descargue screaming frog. Vamos a trabajar con la herramienta gratuita por lo pronto, esta guía nos va a ayudar a que información descargar de screaming frog y combinarla con google analytics y google search console, se que la versión de paga ya te extrae información de las herramientas de google. es un reto con tanta analítica, así que manos a la obra. Gracias por la información. saludos
Definitivamente muy buena herramienta, ojala que pronto sus creadores consideren mejorar su interfaz ya que las veces que la he usado en menos de un minuto salgo huyendo (es terriblemente fea visualmente) pero después de leer toda esta información creo que me tendré que amarrar a la silla 🙂 y así poder exprimirla con las recomendaciones de este articulo.
También quisiera preguntar ya que en este articulo se menciona imagify si es mejor que smush.
Gracias
Hola Sanix!
Realmente la interfaz es fea, pero la herramienta en sí no es compleja de dominar, es simplemente mirar todas las opciones e ir tratando de entenderla.
Cualquier duda puedes preguntar por aquí 😉
Sobre lo de la compresión de imagines (el plugin de imagify), lo pongo porque hablo de las imágenes con extensión .webp y Smush solo es para los formatos de extensión de imagen tradicionales (que yo recuerde). Sobre cual es mejor de las dos, no te sabría decir porque no he realizado una comparativa de ambas.
Saludos!
¡Excelente artículo sobre la guía de Screaming Frog! Esta herramienta es una joya para aquellos que desean mejorar su sitio web y maximizar su rendimiento en línea.